What Is Snowflake and Why Is It Exciting?
.png)



With its valuation of $60 billion, Snowflake is one of the hottest startups right now. You may have seen my post last week digging into why Snowflake is so valuable, which looked at Snowflake solely from a business perspective. This week, let's examine Snowflake from a product perspective.
As a product, you can think of Snowflake as a SQL database that lets you store arbitrarily large datasets (>1PB). Over the past decade, as companies have worked with more and more data, they've needed tools to scale to arbitrarily large datasets. Of the tools that let you work with massive datasets, the most notable are Hadoop, Spark, and Amazon Redshift.
There are three key differentiators that make Snowflake better than these tools:
- It's completely serverless.
- Storage is decoupled from compute.
- You pay only for what you use.
Let's take a look at each of these.
Differentiator #1: Snowflake Is Completely "Serverless"
To get started with Snowflake, all you need to do is sign up for an account and upload some data. You can then immediately start running queries against your data. There's no need to do any capacity planning to figure out how many "Snowflake instances" you need -- you only need one. On top of that, there's no need to provision any servers yourself. Snowflake takes care of everything behind the scenes.
This isn't just an advantage when first signing up. As you use Snowflake, it will autoscale the storage as needed. You never have to worry about running out of disk space. You also don't have to do any sort of server maintenance yourself. Disk failures and server failures are all handled transparently by Snowflake.
Because Snowflake is serverless, it's able to provide the other two key differentiators.
Differentiator #2: Storage is Decoupled from Compute
Traditional databases store the data on the same servers that process the database queries. This is done to minimize the amount of time it takes for the database to access the data, but it also comes with some downsides. If you want to add more compute power to your database, you need to spin up a whole new database cluster and copy the data over.
Instead of storing data on the same machines that process the queries, Snowflake stores the data in S3 and has a separate pool of servers for processing queries. That way, if you want to make your queries faster, all you have to do is tell Snowflake to use more servers to process the queries. The way Snowflake exposes this in the product is pretty neat. Snowflake has a concept of a "virtual warehouse", which, under the hood, corresponds to some number of Snowflake compute servers. When you run a query, you specify which virtual warehouse to run it in.
Each virtual warehouse has a size. There are eight different sizes, with each size containing twice the compute power as the previous one. As an example of how you would use this in practice, let's say you have a virtual warehouse that is size X-Small. It has been working fine for you, but you now want to run a query that would normally take an hour. What you can do is instantaneously resize the virtual warehouse to a 4X-Large, which has 128x the compute as an X-Small. Now when you run the query, it will run approximately 128 times faster and complete in under 30 seconds (this isn't quite true in practice because there are some slowdowns when you attempt to parallelize a query, but the general idea that a larger virtual warehouse will run your queries faster holds true).
Fun fact, the size of your virtual warehouse is the only setting provided by Snowflake that directly affects performance. Compare this to Postgres, which has ~50 settings that directly affect performance. Snowflake likes to phrase this as "the only performance setting is how much performance you want".
Differentiator #3: You Pay Only for What You Use
By separating the compute from the storage, Snowflake is also able to charge you separately for how much storage you use and how much compute you use. The storage cost is $23/TB/month which, by the way, is the exact same price as S3! Snowflake makes no money off of the storage cost and only charges it as a pass-through cost.
As for the compute costs, you only have to pay when you are running a virtual warehouse. For their lowest pricing plan, an X-Small costs $2 per hour it runs, and each virtual warehouse size costs twice as much as the previous size (and provides twice as much compute). Because the storage is decoupled from the compute, you don't need to keep a virtual warehouse running when you aren't running a query. For example, let's say you keep data in Snowflake and over the course of a month, you use one hour of an X-Small. Your total bill for the month will be the $2 for the virtual warehouse and the $23/TB storage fee. This makes Snowflake ideal for use cases where you store lots of data but only need to query a small portion of it or query it infrequently.
Compare this to pricing for Amazon Redshift. For Redshift, you pay for a certain number of nodes and each node comes with a fixed amount of CPU and storage. If you aren't running any queries in Redshift, you still have to pay for the CPU, even though you aren't using it.
In addition to providing the above key differentiators, Snowflake does have a lot of "quality of life" features. These are features that, while not critical to the Snowflake product, do improve the experience of using the product. Here are some of my favorites:
Query History
Out of the box, Snowflake keeps a 14 day history of all the queries run in your account.

This is great for any number of purposes. If you edit a SQL query and forgot the exact query you ran, you can easily find the query in the Snowflake history. You can use this data for auditing and see what queries everyone ran against your data. You can also use it to optimize your performance spend by seeing what queries are consuming the most compute time.
In addition to keeping track of the queries you have run, Snowflake also keeps track of results of each query for 24 hours:
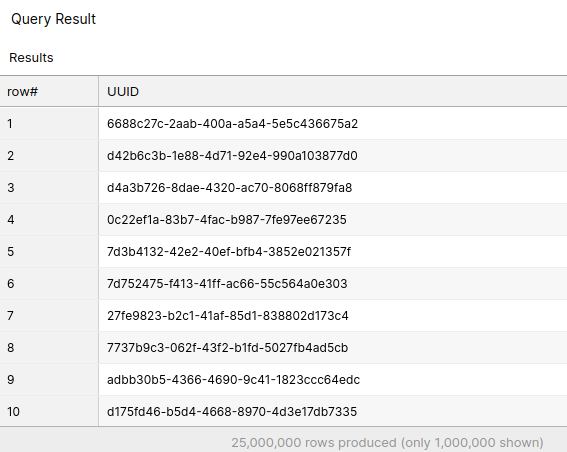
If you forgot to store the results of your query somewhere, Snowflake will have already done that for you. If you have the query id of a previous query, you can also use the Snowflake result_scan function to access the results of a previous SQL query from a second SQL query.
Snowflake also includes a query profiler as part of the query history:
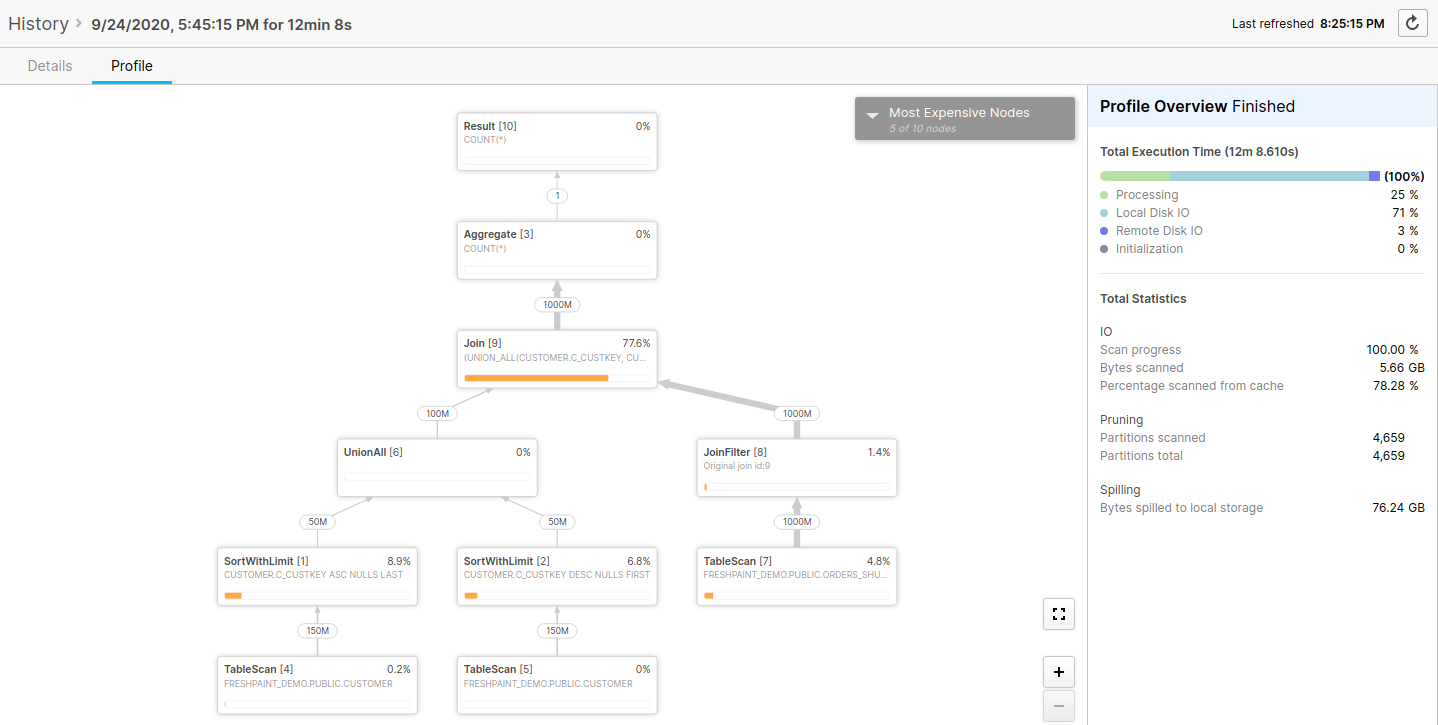
The query profiler shows you the query plan for your query, how much time was spent in each part of the query plan, and how much data was processed by each part of the query plan. This information is invaluable for optimizing slow queries and Snowflake automatically records this information for you.
Materialized Views
In most databases, a materialized view contains the results of a query run at some point in time. Because of this, the data in a materialized view can be stale. Materialized views in Snowflake work a bit differently. Materialized views in Snowflake automatically update, but there are a number of limitations. For example, a materialized view in Snowflake can't include a join.
One use case for materialized views is to keep track of aggregations on top of a raw table. If you have an orders table that keeps track of the different product orders someone has made and you want to keep track of the average and total spend by each customer, you can do that with a materialized view:
{% c-block language="sql" %}
CREATE MATERIALIZED VIEW customer_aggregates AS
SELECT customer_id, SUM(cost) AS total_spend, AVG(cost) AS avg_spend
FROM orders
GROUP BY customer_id;
{% c-block-end %}
You can also use a materialized view to preemptively filter for specific rows from a table. For example, you may place particular importance on orders that have a cost of over $100 and want queries over high valued orders to be fast:
{% c-block language="sql" %}
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT * FROM orders
WHERE cost > 100;
{% c-block-end %}
So even though there are limitations with Snowflake's materialized views, the fact that they auto-update has tons of advantages.
Data Sharing
Because storage is decoupled from the compute in Snowflake, Snowflake is able to do some pretty neat things with data sharing. The person who pays for the compute can be a completely different person from the person that pays for storage. For example, Starschema provides a Covid-19 dataset on Snowflake. Starschema only has to pay the storage costs for the dataset, but they can give access to the dataset to many other companies. Whenever a company queries the dataset, they and not Starschema pay for the compute costs.
When a table is shared with you, it appears in your account as if it were an ordinary Snowflake table. This means you can join it with any tables that are private to your account without any extra ETL process! This makes it possible to combine datasets from multiple different third party and first party sources without any hassle.
.jpg)
.jpg)
.jpg)







.png)
